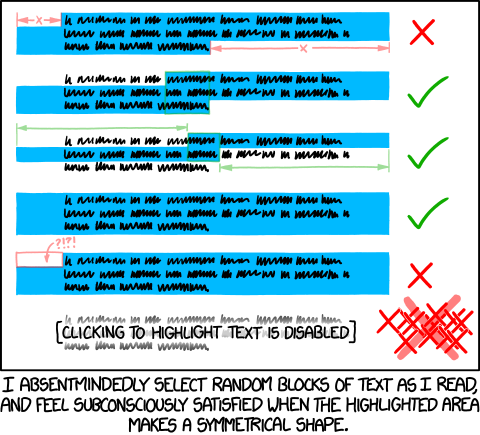
During May 2012, I was reading about seam carving, an interesting and almost magical algorithm which could rescale images without apparently squishing it. After playing with the the little seams that the seam carver tended to generate, I noticed that they tended to converge arrange themselves in a way that cut through the spaces in between letters (dynamic programming approaches are actually fairly common when it comes to letter segmentation, but I didn't know that). It was then, while reading a particularly verbose smbc comic, I thought that it should be possible to come up with something which would read images (with <canvas>), figure out where lines and letters were, and draw little selection overlays to assuage a pervasive text-selection habit.
My first attempt was simple. It projected the image onto the side, forming a vertical pixel histogram. The significant valleys of the resulting histograms served as a signature for the ends of text lines. Once horizontal lines were found, it cropped each line, and repeated the histogram process, but vertically this time, in order to determine the letter positions. It only worked for strictly horizontal machine printed text, because otherwise the projection histograms would end up too noisy. For one reason or another, I decided that the problem either wasn't worth tackling, or that I wasn't ready to.
Fast forward a year and a half, I'm a freshman at MIT during my second month of school. There's a hackathon that I think I might have signed up for months in advance, marketed as MIT's biggest. I slept late the night before for absolutely no particular reason, and woke up at 7am because I wanted to make sure that my registration went through. I walked into the unfrozen ice rink, where over 1,000 people were claiming tables and splaying laptop cables on the ground— so this is what my first ever hackathon is going to look like.
Everyone else was "plugged in" or something; big headphones, staring intently at dozens of windows of Sublime Text. Fair enough, it was pretty loud. I had no idea what I would have ended up doing, and I wasn't able to meet anyone else who was both willing to collaborate and had an idea interesting enough for me to want to. So I decided to walk back to my dorm and take a nap.
I woke up from that nap feeling only slightly more tired, and nowhere closer to figuring out what I was going to do. I decided to make my way back to the hackathon, because there's free food there or something.
If you paid attention to the permissions requested in the installation dialog, you might have wondered about why exactly this extension requires such sweeping access to your information. Project Naptha operates a very low level, it's actually ideally the kind of functionality that gets built in to browsers and operating systems natively. In order to allow you to highlight and interact with images everywhere, it needs the ability to read images located everywhere.
One of the more impressive things about this project is the fact that it's almost entirely written in client side javascript. That means that it's pretty much totally functional without access to a remote server. That does come at a bit of a caveat, which is that online translation running offline is an oxymoron, and lacking access to a cached OCR service running in the cloud means reduced performance and lower transcription accuracy.
So there is a trade-off that has to happen between privacy and user experience. And I think the default settings strike a delicate balance between having all the functionality made available and respecting user privacy. I've heard complaints on both sides (roughly equal in quantity, actually, which is kind of intriguing)— lots of people want high quality transcription to the default, and others want no server communication whatsoever as the default.
By default, when you begin selecting text, it sends a secure HTTPS request containing the URL of the specific image and literally nothing else (no user tokens, no website information, no cookies or analytics) and the requests are not logged. The server responds with a list of existing translations and OCR languages that have been done. This allows you to recognize text from an image with much more accuracy than otherwise possible. However, this can be disabled simply by checking the "Disable Lookup" item under the Options menu.
The translation feature is currently in limited rollout, due to scalability issues. The online OCR service also has per-user metering, and so such requests include a unique identifier token. However, the token is entirely anonymous and is not linked with any personally identifiable information (it handled entirely separately from the lookup requests).
So actually, the thing that is running on this page isn't the fully fledged Project Naptha. It's essentially just the front-end, so it lacks all of the computational heavy lifting that actually makes it cool. All the text metrics and layout analyses were precomputed. Before you raise your pitchforks, there's actually a good reason this demo page runs what amounts to a Weenie Hut Jr. version of the script.
The computationally expensive backend uses WebWorkers extensively, which, although has fairly good modern browser support, has subtle differences between platforms. Safari has some weird behavior when it comes to sending around ImageData instances, and transferrable typed arrays are slightly different in Firefox and Chrome. Most importantly though, the current stable version (34) of Google Chrome, at time of writing actually suffers from a debilitatingly broken WebWorkers implementation. Rather fortunately, Chrome extensions don't seem to suffer from the same problem.
The dichotomy between words expressed as text and those trapped within images is so firmly engrained into the browsing experience, that you might not even recognize it as counter-intuitive. For a technical crowd, the limitation is natural, lying in the fact that images are fundamentally “raster” entities, devoid of the semantic information necessary to indicate which regions should be selectable and what text is contained.

Computer vision is an active field of research essentially about teaching computers how to actually “see” things, recognizing letters, shapes and objects, rather than simply pushing copies of pixels around.

In fact, optical character recognition (OCR) is nothing new. It has been used by libraries and law firms to digitize books and documents for at least 30 years. More recently, it has been combined with text detection algorithms to read words off photographs of street signs, house numbers and business cards.

The primary feature of Project Naptha is actually the text detection, rather than optical character recognition. It runs an algorithm called the Stroke Width Transform, invented by Microsoft Research in 2008, which is capable of identifying regions of text in a language-agnostic manner. In a sense that’s kind of like what a human can do: we can recognize that a sign bears written language without knowing what language it's written in, nevermind what it means.
However, half a second is still quite noticeable, as studies have shown that users not only discern, but feel readily annoyed by delays as short as a hundred milliseconds. To get around that, Project Naptha is actually continually watching cursor movements and extrapolating half a second into the future so that it can kick off the processing in advance, so it feels instantaneous.
In conjunction with other algorithms, like connected components analysis (identifying distinct letters), otsu thresholding (determining word spacing), disjoint set forests (identifying lines of text), Project Naptha can very quickly build a model of text regions, words, and letters— all while completely unaware of the specifics, what specific letters exist.
Once a user begins to select some text, however, it scrambles to run character recognition algorithms in order to determine what exactly is being selected. This recognition process happens on a per-region basis, so there’s no wasted effort in doing it before the user is done with the final selection.
The recognition process involves blowing up the region of interest so that each line is on the order of 100 pixels tall, which can be as large as a 5x magnification. It then does an intelligent color masking filter before sending it to a built-in pure-javascript port of the open source Ocrad OCR engine.
Because this process is relatively computational expensive, it makes sense to do this type of “lazy” recognition- staving off until the last possible moment to run the process. It can take as much as five to ten seconds to complete, depending on the size of the image and selection. So there’s a good chance that by the time you hit Ctrl+C and the text gets copied into your clipboard, the OCR engine still isn’t done processing the text.
That’s all okay though, because in place of the text which is still getting processed, it inserts a little flag describing where the selection is and which part of the image to read from. For the next 60 seconds, Naptha tracks that flag and substitutes it with the final, recognized text as soon as it can.
Sometimes, the built-in OCR engine isn’t good enough. It only supports languages with the Latin alphabet and a limited number of diacritics, and doesn’t contain a language model so that it outputs a series of letters dependent on the probability given its context (for instance, the algorithm may decide that “he1|o” is a better match than “hello” because it only looks at the letter shape). So there’s the option of sending the selected region over to a cloud based text recognition service powered by Tesseract, Google’s (formerly HP’s) award-winning open-source OCR engine which supports dozens of languages, and uses an advanced language model.
If anyone triggers the Tesseract engine on a public image, the recognition result is saved, so that future users who stumble upon the same image will instantaneously load the cached version of the text.
There is a class of algorithms for something called “Inpainting”, which is about reconstructing pictures or videos in spite of missing pieces. This is widely used for film restoration, and commonly found in Adobe Photoshop as the “Content-Aware Fill” feature.
Project Naptha uses the regions detected as text as a mask for a particular inpainting algorithm developed in 2004 based on the Fast Marching Method by Alexandru Telea. This mask can be used to fill in the spots where the text is taken from, creating a blank slate for which new content can be printed.
With some rudimentary layout analysis and text metrics, Project Naptha can figure out the alignment parameters of the text (centered, justified, right or left aligned), the font size and font weight (bold, light or normal). With that information, it can reprint the text in a similar font, in the same place. Or, you can even change the text to say whatever you want it to say.
It can even be chained to an online translation service, Google Translate, Microsoft Translate, or Yandex Translate in order to do automatic document translations. With Tesseract’s advanced OCR engine, this means it’s possible to read text in languages with different scripts (Chinese, Japanese, or Arabic) which you might not be able to type into a translation engine.

The prototype which was demonstrated at HackMIT 2013, later winning 2nd place, was rather blandly dubbed "Images as Text". Sure, it pretty aptly summed up the precise function of the extension, but it really lacked that little spark of life.
So from then, I set forth searching for a new name, something that would be rife with puntastic possibilities. One of the possibilities was "Pyranine", the chemical used in making the ink for flourescent highlighters (my roommate, a chemistry major, happened to be rather fond of the name). I slept on that idea for a few nights, and realized that I had totally forgotten how to spell it, and so it was crossed off the candidate list.
Naptha, its current name, is drawn from an even more tenuous association. See, it comes from the fact that "highlighter" kind of sounds like "lighter", and that naptha is a type of fuel often used for lighters. It was in fact one of the earliest codenames of the project, and brought rise to a rather fun little easter egg which you can play with by quickly clicking about a dozen times over some block of text inside a picture.










{kind=link}